
Ever wondered why ChatGPT or Claude sometimes cuts off your response, forgets context, or gives vague answers?
It’s not magic — it’s tokens.
In simple terms, tokens are the building blocks of your AI conversation.
Understanding how they work can help you write better prompts, save costs, and get smarter, more focused outputs.
Before we dive in, check out 7 Proven ChatGPT Techniques Every Advanced User Should Know — it’ll give you a strong foundation in prompt optimization.
1. What Are Tokens (in Plain English)?
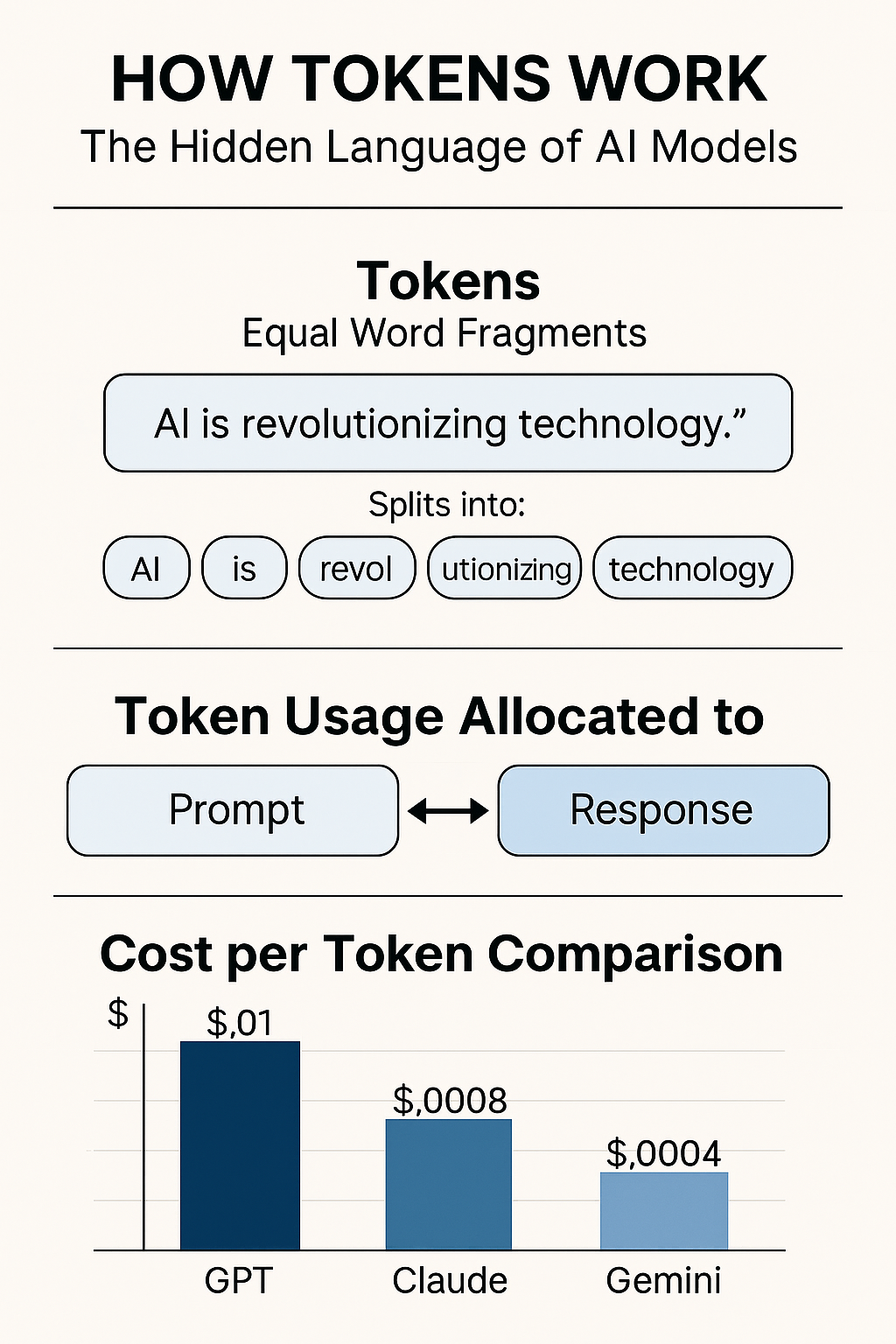
Think of tokens as puzzle pieces of language that AI uses to understand and generate text.
Each token isn’t exactly a word — it’s more like a fragment of one.
For example:
- The word “Artificial” might be split into tokens like “Art”, “ificial”
- A full sentence like “AI is amazing!” might equal 4–6 tokens
In most models:
- 1 token ≈ 4 characters (or about ¾ of a word in English)
- 1,000 tokens ≈ 750 words
Every prompt you send — and every response you get — uses up tokens from a context window, which is like the AI’s short-term memory.
For a deeper breakdown, read Beginners Guide to AI Terms You Actually Need to Know.
2. Why Prompt Length Matters
Your prompt length determines:
- How much information the AI can remember (context window)
- How much your response costs (token-based pricing)
- How consistent your results are
Every large language model (LLM), such as GPT-4, Claude, or Gemini, has a maximum token limit (e.g., 200K tokens for Claude 3.5 Sonnet or 128K for GPT-4 Turbo).
If your prompt exceeds that limit, the model:
- Truncates earlier context
- Produces incomplete or less accurate results
- May “forget” previous instructions
💡 Think of it like memory overflow — the longer your prompt, the less space remains for the AI’s response.
To understand how different models handle this, see How to Choose the Right AI Model for Your Workflow.
3. Tokens = Cost
Every token also costs money when using APIs like OpenAI or Anthropic.
That means shorter, more precise prompts are not just faster — they’re cheaper.
| Platform | Model | Cost per 1K Input Tokens | Max Context |
|---|---|---|---|
| OpenAI | GPT-4 Turbo | ~$0.01 | 128K |
| Anthropic | Claude 3.5 Sonnet | ~$0.008 | 200K |
| Gemini 1.5 Pro | ~$0.004 | 1M+ |
If you use too many tokens, your AI assistant becomes more expensive and slower.
Efficient prompting, as explained in 5 Advanced Prompt Patterns for Better AI Outputs, helps you minimize waste.
4. How to Write Token-Efficient Prompts
Here’s how to get more from fewer tokens: Be concise but specific.
Instead of:
“Please explain in great detail every possible way one might use AI in digital marketing.”
Try:
“Summarize 5 practical AI use cases for digital marketing teams.”
Avoid repeating instructions.
Use structured prompts (bullet points, numbered lists).
Leverage system prompts in tools like LangChain Agents to control tone and behavior efficiently.
💡 Tip: You can test prompt sizes using tools like OpenAI’s tokenizer or the VS Code extension CodeGPT, covered in VS Code Extensions Every AI Developer Should Know.
5. The Role of Tokens in AI Architecture
Each model has its own architecture — which affects how tokens are processed.
For instance:
- GPT uses transformer layers to assign weight (importance) to each token.
- Claude emphasizes context compression, allowing it to handle longer documents efficiently.
- Gemini integrates multi-modal tokenization, converting images and text together.
For an easy-to-understand breakdown of model design, read Get Better AI Results: Master the Basics of AI Architecture.
6. What Happens When You Hit the Token Limit?
When your input + output exceeds the model’s limit:
- Older parts of the conversation are dropped
- Responses become inconsistent or cut short
- Summarization is used to “compress” prior context
This is where Retrieval-Augmented Generation (RAG) comes in — it helps by storing data externally and feeding only what’s needed back into the model.
You can learn more in How to Improve Your AI with Retrieval-Augmented Generation.
7. Quick Reference: Token Tips for Everyday Use
| Goal | Token Strategy | Example |
|---|---|---|
| Save cost | Use concise prompts | “List 3 main points.” |
| Improve quality | Include relevant context | “Using the notes below, summarize key ideas.” |
| Extend context | Use RAG or vector databases | “Search my docs for related info first.” |
| Debug length issues | Track token count | Use tokenizer tools or API logs |
Key Takeaways for Better AI Interactions
To summarize, understanding tokens transforms how you interact with AI tools. Remember these essential points:
- Tokens are the fundamental units of AI text processing, not just words
- Both prompts and responses consume tokens from your available budget
- Concise, structured prompts typically yield better results than verbose ones
- Context window limits require strategic conversation management
- Token optimization directly impacts response quality and cost-effectiveness
By applying these principles, you’ll unlock your AI potential and get significantly better results from every interaction.
Conclusion: Small Tokens, Big Difference
Tokens are the currency of AI communication — every prompt, response, and insight is powered by them.
Once you understand how they work, you gain total control over cost, clarity, and context.
Mastering tokens is like learning the rhythm of AI.
And when you get that rhythm right — your prompts hit smarter, faster, and sharper.

