
If you’ve built anything with AI — whether it’s a chatbot, data analyzer, or automation — you’ve probably noticed one big challenge: efficiency.
Every API call, model query, and data transfer adds up. The result? Higher latency, unnecessary costs, and slower user experiences.
That’s where batching, caching, and rate limiting come in.
These three techniques form the backbone of scalable, reliable AI systems.
They ensure your workflows stay fast, cost-efficient, and stable — even under heavy use.
If you’re new to building AI pipelines, you might want to start with our Introduction to LangChain Agents or How to Use ChatGPT and Zapier to Automate Your Content Calendar for hands-on automation fundamentals.
1. Batching: Process More with Fewer Requests
Batching is the simplest — yet most powerful — optimization technique.
Instead of sending dozens of small API requests to your model, you group multiple inputs together in a single request.
Example:
- ❌ 10 separate GPT API calls = 10 round trips, 10 charges
- ✅ 1 batched API call = 1 round trip, 1 set of compute
Why it matters:
- Faster performance: Reduces latency by minimizing network calls
- Lower costs: Fewer API requests = lower billing
- Scalable design: Ideal for batch processing (e.g., summarizing 50 documents or analyzing multiple messages at once)
Tools like LangChain, OpenAI SDK, and Replit Agents natively support batching.
If you’re automating data pipelines, check out How to Build Complex Workflows with AI Copilots and Zapier for real-world examples.
2. Caching: Stop Re-Calculating What You Already Know
Caching is like giving your AI memory.
When a user or workflow repeats a similar query, the system reuses a stored response instead of recalculating from scratch.
Think of it as your AI’s personal notebook — once it writes something down, it doesn’t need to think about it again.
Example:
If your app translates “Hello, world!” multiple times, caching prevents paying for that same GPT call repeatedly.
Benefits:
- Speed: Cached responses return instantly.
- Cost-effective: Saves on repeated API requests.
- Consistency: Ensures predictable results for repeated tasks.
Caching frameworks like LangChain’s in-memory cache or Redis make this easy to implement in production.
To go deeper into structured reasoning and prompt reuse, see Prompt Chaining Made Easy.
3. Rate Limiting: Protect Your AI from Overload
Rate limiting acts as a traffic controller for your workflow.
It ensures your system doesn’t exceed API limits or crash under high demand.
Imagine your AI pipeline like a busy highway — without traffic lights, everything jams.
Rate limiting spaces out requests, keeping both the model and your infrastructure stable.
Why you need it:
- Prevents throttling: Stay within model API limits (like OpenAI’s tokens per minute).
- Stabilizes performance: Smooths spikes in user activity.
- Improves reliability: Avoids downtime during traffic surges.
For example, Zapier, LangChain, and OpenAI all provide built-in rate limit handlers.
You can also build custom queues using tools like Celery, RabbitMQ, or Redis Streams.
If your workflows are scaling, learn how to manage automation branching in How to Use Zapier Filters and Paths for Complex Automations.
4. Combining All Three for Smarter AI Systems
When batching, caching, and rate limiting work together, you get:
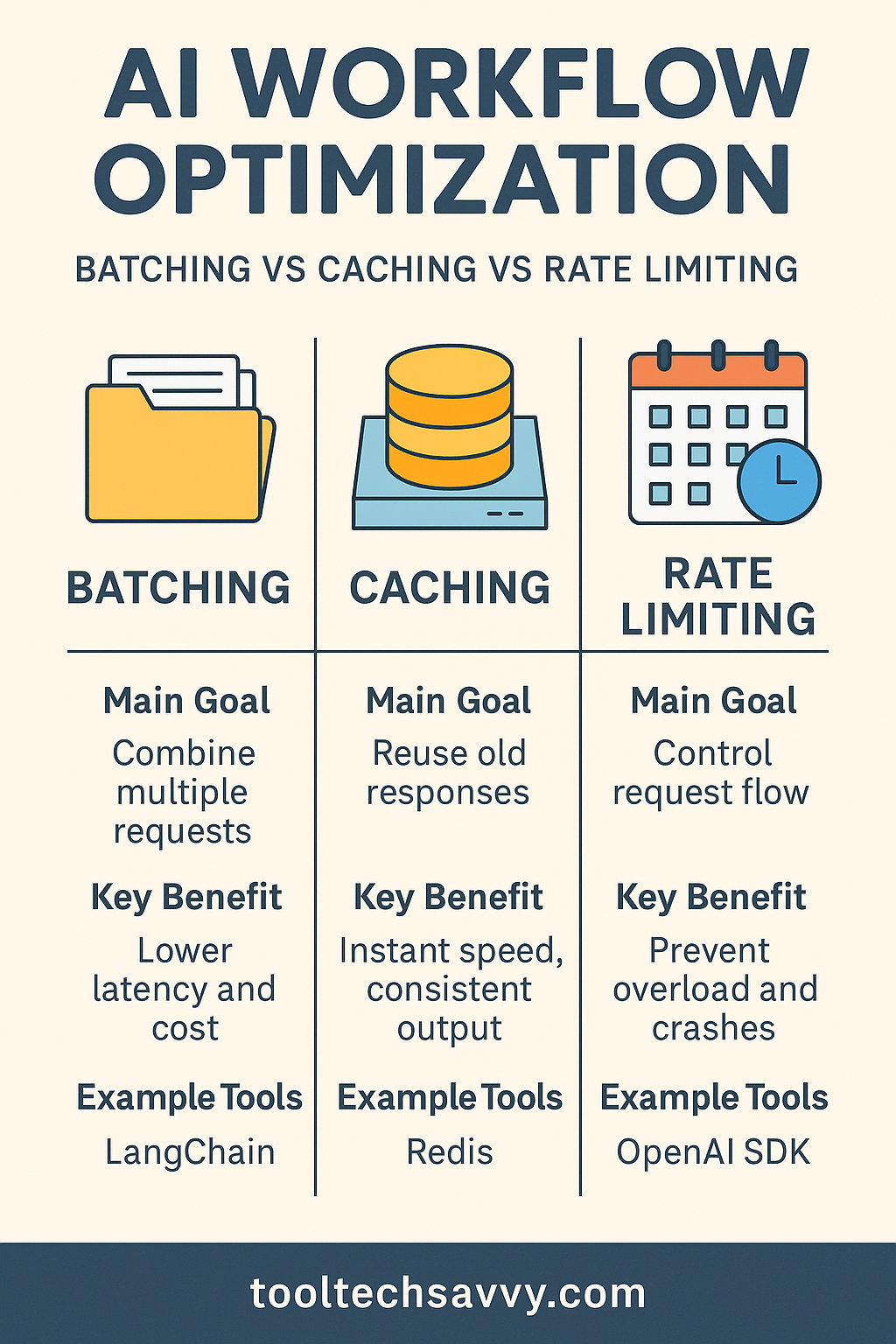
| Technique | Main Goal | Key Benefit |
|---|---|---|
| Batching | Combine multiple requests | Lower latency and cost |
| Caching | Reuse old responses | Instant speed, consistent output |
| Rate Limiting | Control request flow | Prevent overload and crashes |
Together, these form the foundation of efficient AI architecture — crucial for developers using OpenAI, Anthropic, or Gemini APIs.
To understand how this fits into larger system design, see Get Better AI Results: Master the Basics of AI Architecture.
5. Example: Optimizing a Real-World AI Pipeline
Imagine you’re building an AI workflow that summarizes articles from URLs.
Here’s what an optimized setup looks like:
1️⃣ Batching: Collect 10 URLs → send them in a single GPT request.
2️⃣ Caching: Store summaries in Redis → skip repeated summaries later.
3️⃣ Rate Limiting: Set 1 request per second → avoid hitting OpenAI API limits.
Result:
70% faster processing,
40% lower cost,
100% more stable pipeline.
6. Why Optimization Is the Secret Skill for AI Developers
In 2025, the best AI developers aren’t the ones writing the longest prompts — they’re the ones building the most efficient systems.
Whether you’re using ChatGPT, Claude, or Gemini, understanding backend optimization unlocks faster apps, smoother automations, and smarter scaling.
Combine this guide with 7 Proven ChatGPT Techniques Every Advanced User Should Know to master both the art of prompting and the science of system design.
Conclusion: Build Fast, Think Smart
Optimizing AI workflows is about working with the model — not against it.
By implementing batching, caching, and rate limiting, you:
✅ Speed up performance
✅ Reduce costs
✅ Build systems that scale effortlessly
So, the next time your workflow feels slow or expensive — it’s not your AI that’s the problem.
It’s your architecture.

