
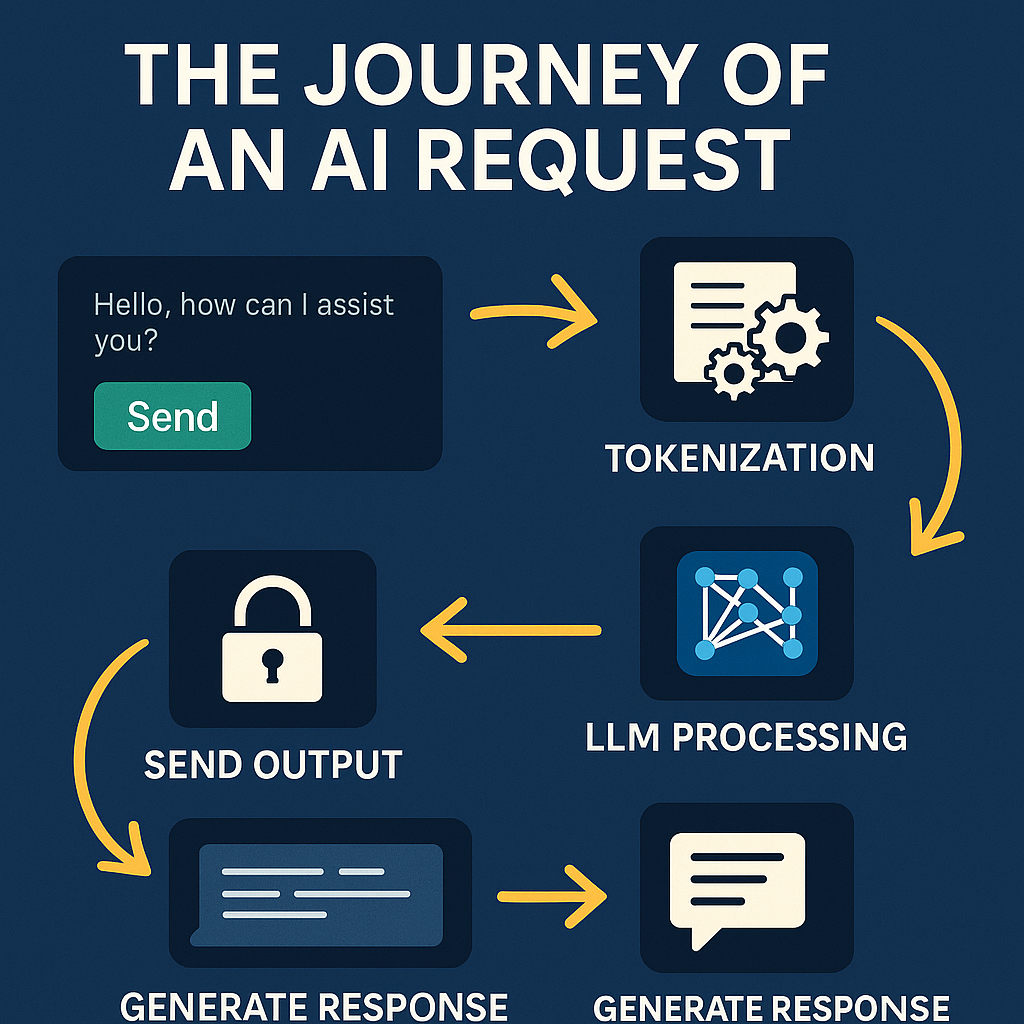
When you type a prompt and hit enter, your words begin an intricate journey through layers of technology, computation, and intelligence. Understanding this process reveals both the remarkable engineering behind AI systems and practical insights for getting better results.
The Moment of Transmission
Your request doesn’t travel directly to an AI model. First, it passes through your application interface—whether that’s a web browser, mobile app, or API integration. The text is packaged into a structured format, typically JSON, along with metadata like conversation history, system instructions, and configuration parameters.
This package then travels across the internet to the AI provider’s servers. For services like Claude or ChatGPT, this means reaching distributed data centres optimized for handling millions of simultaneous requests. Load balancers route your specific request to available infrastructure, ensuring efficient processing even during peak usage.
Tokenization: Breaking Down Your Words
Before your prompt reaches the AI model, it undergoes tokenization—a crucial pre-processing step that converts your human-readable text into numerical tokens the model can understand. This isn’t simple word splitting; tokenization breaks text into sub-word units based on frequency patterns in the training data.
For example, common words like “the” become single tokens, while rare or technical terms might split into multiple tokens. This process affects everything from model performance to costs, since most AI services charge based on token count rather than character count. Understanding tokenization helps explain why concise, focused prompts often yield better results than verbose ones.
The Neural Network Awakens
With your tokenized prompt ready, the actual AI processing begins. Modern language models like GPT-4 or Claude use transformer architectures—neural networks with billions of parameters trained on vast text corpora. Your tokens flow through multiple layers of this network, each applying complex mathematical transformations.
The model doesn’t “understand” your request the way humans do. Instead, it processes patterns learned during training, calculating probabilities for what tokens should come next based on the input context. This happens through attention mechanisms that weigh the relevance of different parts of your prompt, allowing the model to focus on key information while generating responses.
The computational requirements are substantial. Processing a single request might involve trillions of mathematical operations across specialized hardware like GPUs or TPUs. Yet this happens in seconds, thanks to optimized infrastructure and parallel processing capabilities.
Context Windows and Memory Management
Your current prompt doesn’t exist in isolation. Most AI systems maintain a context window—the combined token count of your conversation history plus the current request. This context determines what information the model can reference when generating responses.
When conversations grow long, older messages may get truncated or summarized to fit within token limits. This is why AI assistants sometimes “forget” details from earlier in extended conversations. Understanding context window management helps you structure conversations more effectively, placing critical information strategically.
Generation: Creating Your Response
Response generation happens token by token in an autoregressive process. The model predicts the most likely next token based on your prompt and all previously generated tokens, then feeds that prediction back as input to generate the subsequent token. This continues until the model produces a stop token or reaches a length limit.
This sequential generation explains why responses appear to “stream” in real-time interfaces. The model isn’t typing the full answer and revealing it gradually—it’s actually generating each word as you see it appear.
Temperature and other sampling parameters influence this generation process. Lower temperatures make responses more focused and deterministic, while higher values increase randomness and creativity. These settings determine whether the model always picks the highest-probability token or samples from a broader distribution of possibilities.
Post-Processing and Safety Filters
Before you see the response, it typically passes through additional layers of processing. Safety systems screen for potentially harmful content, checking against policies on violence, illegal activities, personal information, and other concerns. Content filters might modify or block responses that violate these guidelines.
The system may also apply formatting, converting markdown syntax into rendered output or structuring code blocks appropriately. Citation systems add source references when responses draw from web search results or retrieved documents.
Practical Implications for Better Prompting
Understanding this journey reveals several strategies for more effective AI interaction:
Be specific and structured. Since models process your entire prompt as context, clear organization helps the attention mechanisms focus appropriately. Structured prompts with explicit instructions typically outperform vague requests.
Manage your context wisely. For complex tasks, consider breaking them into smaller conversations rather than one enormous thread. This keeps relevant context within the model’s attention span and prevents token limit issues.
Understand token economics. If you’re using API access, optimizing for token efficiency can significantly reduce costs without sacrificing quality. Removing unnecessary words and using parameter-efficient techniques helps maximize your budget.
Leverage system patterns. Models respond better to formats they encountered during training. Using common patterns like role-based prompting, chain-of-thought reasoning, or few-shot examples aligns with how these systems process information most effectively.
The Return Journey
Your generated response travels back through the infrastructure stack, passing through the same load balancers and network layers. The application interface receives the formatted output and displays it on your screen. The entire round trip—from your keystroke to rendered response—typically completes in just a few seconds.
But the journey doesn’t necessarily end there. Your interaction becomes part of the conversation history, affecting subsequent exchanges. Some systems use conversations to improve future models through feedback loops and fine-tuning, though this depends on specific privacy policies and opt-in settings.
Looking Forward
As AI technology evolves, this journey continues to change. Newer architectures promise more efficient processing, longer context windows, and better reasoning capabilities. Multimodal models can process images, audio, and video alongside text, adding new dimensions to how requests are interpreted and responses generated.
Understanding what happens when you hit ‘send’ transforms AI from a mysterious black box into a comprehensible system with specific strengths, limitations, and optimal use patterns. This knowledge empowers you to craft better prompts, anticipate system behaviour, and ultimately get more value from these powerful tools.
The next time you interact with an AI assistant, remember the remarkable infrastructure and computational sophistication working behind that simple text box. Your words set in motion a cascade of technology that would have seemed like science fiction just years ago—yet it’s now as simple as hitting ‘send’.Retry

