
Every time your phone unlocks with your face, or your email filters out spam, or a chatbot answers your question — a neural network is quietly doing the heavy lifting behind the scenes. Neural networks are one of the most important ideas in modern AI, and yet most explanations of how they work dive straight into the mathematics without ever making it feel real.
This post is different. We’re going to break open a neural network and look at its layers — what they are, what each one actually does, and why it’s structured the way it is. No maths degree required.
Who this is for If you’re curious about AI but find technical jargon off-putting, you’re in the right place. We’ll build understanding from everyday analogies before introducing any terms.
Start here: What is a neural network?
A neural network is a computer program loosely inspired by the human brain. Just as your brain contains billions of neurons connected to each other, a neural network contains thousands (sometimes millions) of tiny mathematical units — also called neurons or nodes — wired together in a chain.
That chain is made up of layers. Each layer is simply a group of neurons that process information together and pass their results along to the next group. Think of it like a factory assembly line, where each station receives raw material, does a specific job, and passes the result to the next station until you get a finished product at the end.
A layer is a group of neurons that process information together and hand their result to the next group — like stations on a factory assembly line.
The big picture: A diagram of the three layer types
Every neural network — no matter how simple or complex — has exactly three kinds of layers. Here’s how they look and how information flows through them:
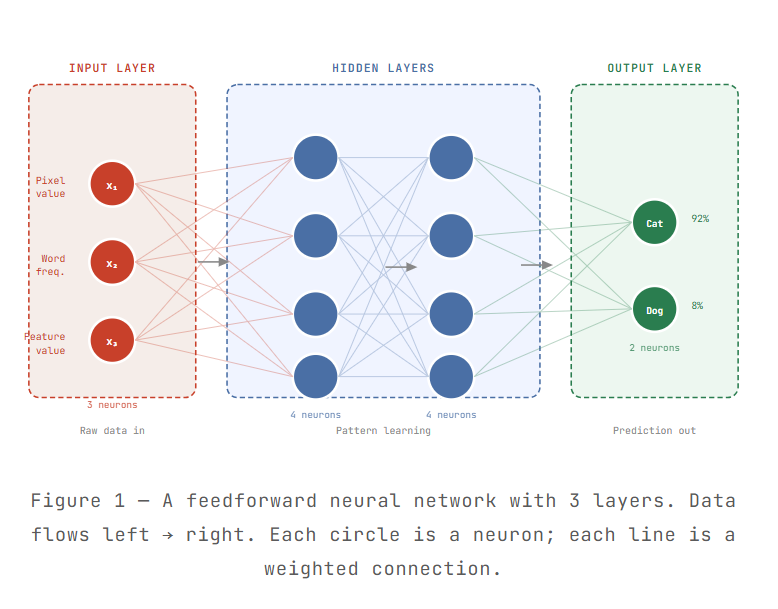
The input layer — where data enters
The input layer is the front door of the neural network. It doesn’t do any computation — its only job is to receive your data and pass it in. Every neuron in the input layer holds exactly one piece of raw information.
Think of it like loading luggage onto a conveyor belt at the airport. Each bag (data point) gets its own slot on the belt. The belt doesn’t care what’s inside the bags — it just moves them along.
Concrete example Imagine you’re training a network to classify photos of cats and dogs. Each photo is 28×28 pixels = 784 pixels. The input layer would have 784 neurons, one per pixel. Each neuron gets a number between 0 and 255 representing that pixel’s brightness.
The number of neurons in the input layer always equals the number of features in your data. More complex data means more input neurons — a 1024×1024 colour image, for instance, would need over 3 million input neurons.
Hidden layers — where the real learning happens
Hidden layers are the heart of the neural network. They sit between the input and output, invisible to the outside world — hence the name “hidden.” This is where the network learns to spot patterns, combine low-level details into high-level concepts, and make sense of complex data.
Each hidden neuron receives signals from every neuron in the previous layer, multiplies each signal by a learned weight (a number that reflects importance), adds them up, and then passes the result through an activation function that decides whether to “fire” the neuron.
You can think of a hidden neuron like a specialist at a company — it listens to all the data coming in, weighs what matters most, and passes a verdict to the next team.
Building up from simple to complex
A key insight about hidden layers is that they work hierarchically. Earlier layers detect simple patterns (edges, colours, short words), and later layers combine those into complex patterns (shapes, faces, sentences). This is how a network trained on millions of photos “learns” what a cat looks like — it doesn’t know the concept of “cat” from the start; it builds that understanding layer by layer.
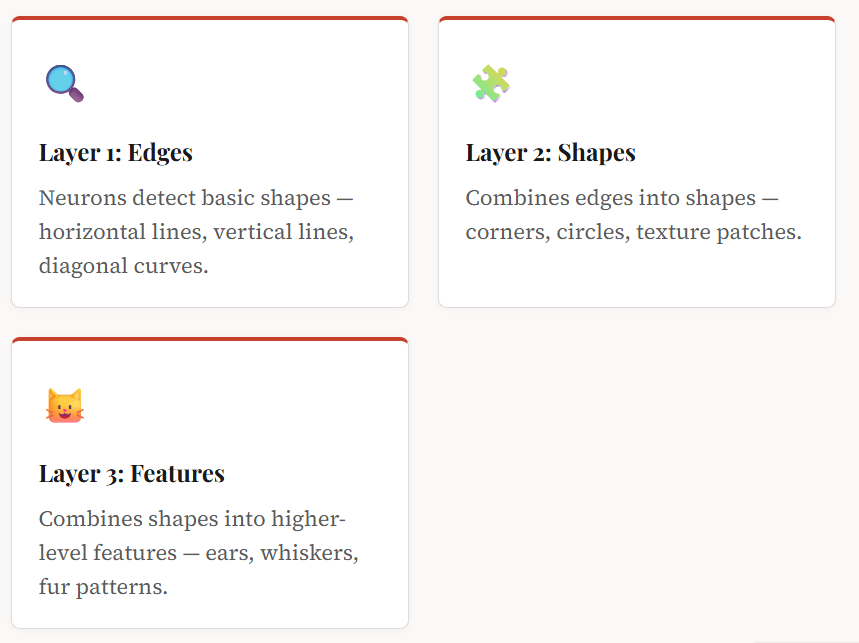
How many hidden layers do you need?
Simple problems (like classifying whether an email is spam) might only need one hidden layer with a handful of neurons. Complex tasks — understanding speech, generating images, translating languages — can require dozens or even hundreds of hidden layers. Deep networks (those with many hidden layers) are the origin of the term deep learning.
The output layer — where the answer lives
The output layer is the network’s conclusion. After the hidden layers have processed and refined the information, the output layer presents a final answer. The number of neurons in the output layer depends on what kind of problem you’re solving:
| Task type | Output neurons | Example |
|---|---|---|
| Binary classification | 1 neuron (yes/no) | Spam or not spam? |
| Multi-class classification | One per class | Cat, Dog, or Rabbit? → 3 neurons |
| Regression (predicting a number) | 1 neuron | What’s tomorrow’s temperature? |
| Multi-label classification | One per label | Which emotions are in this photo? |
The output from each output neuron is usually a probability. In our cat/dog example, the network might output Cat: 0.92, Dog: 0.08 — meaning it’s 92% confident the photo shows a cat.
Putting it all together
Here’s a quick walkthrough of what happens when you show a neural network a photo and ask it to identify the animal:
Step 1 — Input: The photo is broken into pixels. Each pixel value is fed into one input neuron.
Step 2 — Hidden processing: The signal ripples through the hidden layers. Each layer transforms the information, extracting more abstract patterns with each pass.
Step 3 — Output: The final layer produces probabilities for each possible answer — and the highest probability wins.
Step 4 — Learning: If the network guesses wrong, an algorithm called backpropagation nudges the weights very slightly so the network does better next time. Repeat this millions of times across millions of examples, and the network becomes surprisingly accurate.
Key takeaway Layers are the organizational structure of a neural network. The input layer takes raw data in. Hidden layers extract patterns and build understanding. The output layer delivers a final answer. Together, they let a network go from raw pixels or words all the way to meaningful predictions.
Quick glossary
If you encounter these terms in further reading, here’s what they mean in plain English:
| Term | Plain-language meaning |
|---|---|
| Neuron / node | A single processing unit that receives inputs, does a calculation, and passes output forward. |
| Weight | A number that controls how much influence one neuron has on the next. The network learns by adjusting these. |
| Activation function | A rule that decides whether a neuron’s output is strong enough to “fire” and pass on a signal. |
| Deep learning | Machine learning using neural networks with many hidden layers. |
| Backpropagation | The training algorithm that adjusts weights after each wrong answer, like error-correction for the whole network. |
| Feedforward network | The basic type of neural network where information only flows in one direction: input → hidden → output. |
ToolTechSavvy publishes in-depth, practitioner-focused guides on AI tools, developer workflows, and cloud platforms — written for people who want to genuinely understand the tech, not just skim the surface. Read more at ToolTechSavvy →