
You’ve probably heard that neural networks “learn” from data — but what actually happens the moment you feed a photo, a sentence, or a number into one? How does raw data become a meaningful prediction?
The answer lies in something called the forward pass — the journey data takes from one end of a network to the other. It’s one of the most important ideas in all of modern AI, and it’s far more intuitive than most explanations make it seem.
By the end of this post, you’ll understand exactly what happens at each step — the maths, the mechanics, and the meaning — without needing a background in data science.
What you’ll learn What the forward pass is and why it matters · How each neuron transforms its input · What activation functions do and why they exist · How layers build understanding from the bottom up · What the network’s output actually means
First: a quick recap of layers
If you’ve read our post on neural network layers, you’ll know that every network is organised into three types: an input layer that receives raw data, one or more hidden layers that process it, and an output layer that delivers a final answer.
The forward pass is simply the process of data travelling through all of these layers in order — from input to output — being transformed at each step. Think of it like passing a note down a row of desks in a classroom. Each person reads the note, adds their own calculation, and passes it along. By the time it reaches the end, the note has been shaped by everyone’s contribution.
The forward pass is data’s journey through the network — transformed at each neuron, refined at each layer, until a final answer emerges at the other end.
What happens inside a single neuron?
To understand the full forward pass, we need to start small — with one neuron. Every neuron in a network does the same three things, in the same order, every single time.
1. Receive inputs
The neuron collects signals from all the neurons in the previous layer. Each signal is just a number — it could be a pixel brightness, a word frequency, a temperature reading. Whatever the data happens to be.
2. Multiply by weights and add a bias
Each incoming signal gets multiplied by a weight — a number that controls how much importance that signal gets. Then a small extra number called a bias is added. This is where the network’s learned knowledge lives: in the weights and biases.
3. Apply an activation function
The result is passed through an activation function — a simple mathematical rule that decides whether and how strongly the neuron fires. This step is what lets the network learn non-linear patterns (more on this shortly).
The formula, in plain terms
Written out, a neuron’s calculation looks like this:
output = activation( (input₁ × weight₁) + (input₂ × weight₂) + … + bias ) Multiply each input by its weight, sum everything up, add a bias, then apply the activation function.
Don’t be put off by the notation. In plain English: the neuron asks “given everything I’m being told, and how important each thing is, how strongly should I respond?” The activation function then converts that into a clean, usable output.
Analogy: the vote counter Imagine a panel of judges, each holding up a score card (the input). Some judges carry more weight than others — a senior judge’s score counts for more. The neuron adds up all the weighted scores (plus a small default offset), and the activation function decides: “Given this total, how confident should I be?” A high total means a strong, clear signal. A low total means a weak or negative response.
Weights: where the learning lives
Weights are the most important part of a neural network. Before training, they’re set to small random numbers. During training, they’re adjusted — tiny increments, millions of times — until the network gets good at its task.
A high weight means: “this input is very important — pay a lot of attention to it.” A low or negative weight means: “this input matters less, or actively pushes against my conclusion.” The network learns which inputs matter for each decision, and by how much.
The bias is simpler — it’s an offset that shifts the neuron’s output slightly up or down, giving the network more flexibility. Think of it like a default position. Without a bias, a neuron with zero inputs would always produce zero, no matter what. The bias breaks that constraint.
Activation functions — and why they matter so much
Here’s a question worth sitting with: why do we need an activation function at all? Why not just pass the weighted sum straight through?
The answer is that without activation functions, a neural network — no matter how many layers it has — can only learn straight-line relationships. It would be no more powerful than a single equation. Activation functions introduce non-linearity, which is what allows the network to model complex, curved, real-world patterns.
Activation functions are what separate a powerful learning machine from a glorified calculator. They’re what allow a network to recognise a face, translate a sentence, or compose music.
The most common activation functions
| Function | What it does | When it’s used |
|---|---|---|
| ReLU | If the input is negative, output 0. Otherwise, pass it through unchanged. Simple and fast. | Most hidden layers — the workhorse of deep learning |
| Sigmoid | Squashes any number to a value between 0 and 1 — like a probability. | Binary classification outputs (yes/no answers) |
| Softmax | Converts a list of numbers into probabilities that all add up to 100%. | Multi-class outputs — “is this a cat, dog, or rabbit?” |
| Tanh | Similar to Sigmoid, but outputs values between -1 and 1. Centred at zero. | Hidden layers where negative outputs are meaningful |
ReLU (Rectified Linear Unit) is by far the most commonly used in modern deep learning. Its simplicity is a feature: it trains faster, and it avoids a problem called the vanishing gradient that plagued earlier activation functions. Most of the neural networks running in production today — in voice assistants, recommendation engines, and language models — use ReLU or a close variant in their hidden layers.
Layer by layer: how the forward pass builds understanding
Now that we understand what one neuron does, we can zoom out and watch the whole forward pass unfold across all the layers.
Imagine the network is looking at a photo of a handwritten number “7”. Here’s what happens:
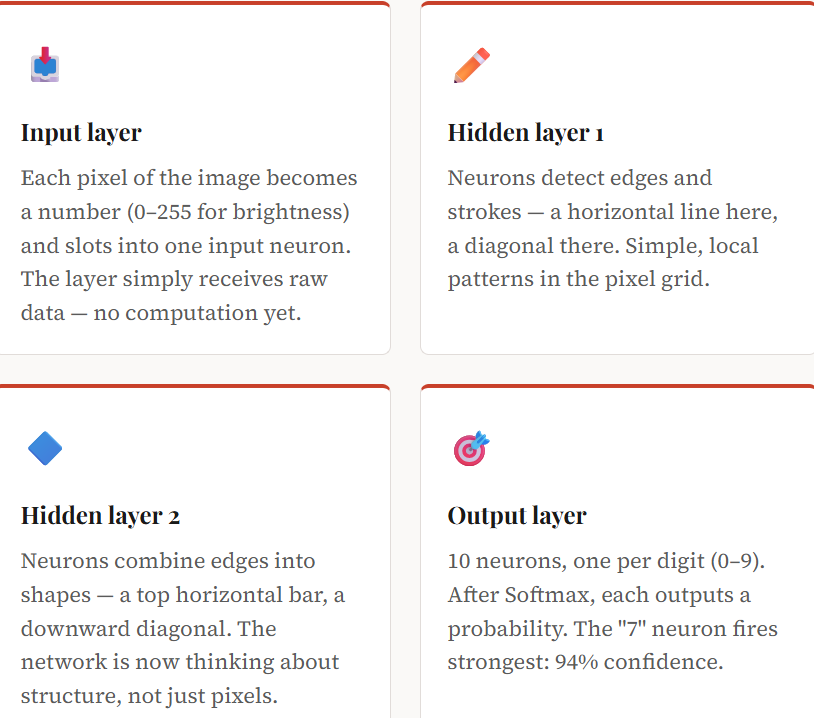
The critical insight: no single layer “understands” the image. Understanding emerges gradually, through the accumulation of transformations. Each layer builds on the work of the previous one, moving from raw pixels toward abstract concepts.
The interactive diagram
The best way to really feel the forward pass is to watch it happen in real time. The animated diagram below shows data flowing through a small network, neuron by neuron, layer by layer. You can pause, adjust the input values, and watch how changing one number ripples through the whole network.
The Forward Pass — Watch data flow through a neural network
Hover any neuron to see its value · Press Play to animate the signal
What does the output actually mean?
When the forward pass completes, the output layer produces a set of numbers. What those numbers represent depends entirely on what the network was trained to do.
In a classification task, the output is typically a list of probabilities — one per class — summing to 100%. The network’s prediction is whichever class has the highest probability. So if you’re classifying emails, and the output is spam: 0.89, not spam: 0.11, the network is saying it’s 89% confident this is spam.
In a regression task (predicting a number rather than a category), the output is a single value — a predicted price, a temperature, a score.
In a generative task (like a language model), the output is a probability distribution over possible next words — the network is saying “given everything so far, here are the odds of each possible next token.”
Forward pass vs. training: an important distinction
It’s worth being clear: the forward pass is not how the network learns. It’s how the network uses what it has already learned.
Learning happens through a separate process called backpropagation, which runs after the forward pass and works in reverse — comparing the network’s output to the correct answer, calculating how wrong it was, and then nudging every weight in the network ever so slightly in a direction that reduces the error. Do this millions of times across a large training dataset, and the weights gradually settle into values that produce accurate predictions.
Once training is complete, the network is deployed and only runs forward passes — no more learning, just prediction. That’s the model you interact with when you use a voice assistant or a spam filter.
| Stage | Direction | Purpose |
|---|---|---|
| Forward pass | Input → Output | Produce a prediction from the current weights |
| Loss calculation | At the output | Measure how wrong the prediction was |
| Backpropagation | Output → Input | Calculate how each weight contributed to the error |
| Weight update | Everywhere | Nudge every weight slightly in the right direction |
Why this matters beyond the theory
Understanding the forward pass isn’t just an academic exercise. It’s the foundation for understanding almost everything else in modern AI:
Why are larger networks more powerful? More layers and neurons means more transformations — more opportunity to extract complex, abstract patterns from data.
Why do language models “hallucinate”? Because the forward pass is always producing the most likely output given the weights — it doesn’t know what it doesn’t know. It’s always generating, never refusing unless trained to.
Why is inference (running a deployed model) expensive? Every query triggers a full forward pass through potentially billions of neurons. GPUs are fast at exactly this kind of parallel arithmetic — which is why they became the hardware backbone of AI.
Key terms, plain and simple
| Term | What it means |
|---|---|
| Forward pass | The journey data takes from the input layer through hidden layers to the output. Produces a prediction. |
| Weight | A number that determines how much influence one neuron has on the next. Adjusted during training. |
| Bias | A constant offset added to a neuron’s output. Gives the network more flexibility. |
| Activation function | A rule applied to a neuron’s output. Introduces non-linearity — the key to learning complex patterns. |
| ReLU | The most common activation function. Outputs 0 for negative inputs, passes positive inputs unchanged. |
| Softmax | Converts a list of raw numbers into probabilities that sum to 100%. Used at the output layer for classification. |
| Inference | Running a trained model on new data — i.e., doing a forward pass without any weight updates. |
| Backpropagation | The learning algorithm that works backwards from the output to adjust weights after each forward pass. |
Enjoying the series? There’s more where this came from.
ToolTechSavvy publishes clear, practitioner-focused guides on AI tools, developer workflows, and cloud infrastructure. No jargon for its own sake — just concepts explained well, with examples that stick. Explore more at ToolTechSavvy →